Overview#
Materials research relies on a combination of manual and semi-automated data management practices. Data acquired from instruments during experiments is typically manually preserved and organized on local systems and transferred to external systems (e.g., researcher laptop or other lab computer) for analysis. Experiment tracking spreadsheets or databases contain essential information needed to understand instrument-collected data. Modeling and simulation data are generated on systems used by researchers and transferred to local systems for analysis (when feasible).
The IMQCAM data management and access architecture is illustrated in Fig. 5.
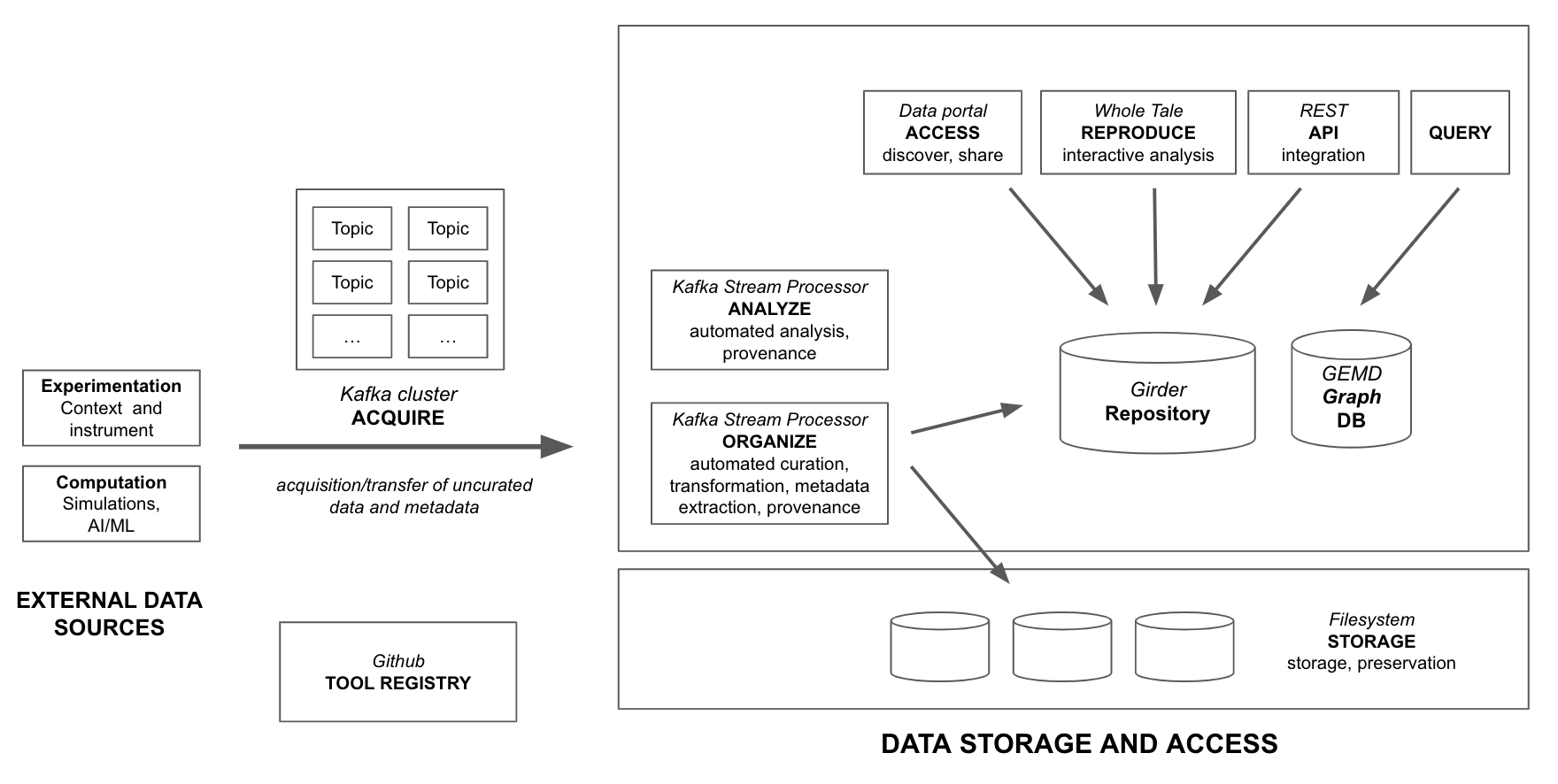
Fig. 5 High-level overview of the IMQCAM data management architecture.#
The HTMDEC provides a centralized solution for materials research data management and access designed support experimental and computational research activities. The system is designed to support the following:
Data acquisition: Acquisition/transfer of uncurated data and metadata from data sources.
Data organization: Manual and automated data curation including
organization, transformation, metadata extraction, and provenance tracking.
Automated data analysis: The ability to deploy automated data analysis components to create derived data products with provenance tracking.
Discovery, access, and sharing: Web and API-based access to data with access control. Containerized interactive analysis environments.
GEMD database: Specialized model and database for tracking and querying material histories.
Tools registry: All software developed as part of the IMQCAM data management platform is managed in GitHub repositories.
Data acquisition#
The primary mode of data acquisition is automated, although researchers and data managers can always manually curate new data collections through the IMQCAM data portal.
Automated data acquisition is achieved through the use of Apache Kafka, an open-source platform for distributed streaming, through OpenMSIStream []. OpenMSIStream is software designed specifically to support generalized experimental and computational materials data streaming. In short, a client application (producer) is installed on each lab server to write data to a specific queue (or topic) in centralized Kafka cluster. Typically the client application monitors a specific folder for changes. Additional client applications (consumers or stream processors) monitor the topic for new events and initiate processing.
Kafka consumer or stream processor applications are developed to handle data source-specific automated curation, transformation, metadata tracking and provenance operations.
Automated data curation and annotation#
Kafka consumers and stream processors serve as the basis for automated data curation and annotation activities. These include the data source-specific organization of files both on the filesystem and in Girder. Automated curation may also conduct format conversions (e.g., from vendor-specific to standard formats), transformation, metadata extraction, and annotation. In all cases, the provenance of data is recorded and associated with each record.
Example
For the JHU laser shock lab, stream processors are used to acquire data from the experiment tracking database and relevant instrument sources. Data from these sources are automically combined so that instrument data can be related back to the experimental context. Vendor-specific formats are converted into standard formats for ease-of-use.
Data storage and preservation#
Data and other asset storage is based on a combination of filesystem and object storage. Most data acquired data objects will be stored on a shared filesystem accessible by higher-level components and to users through the data portal (described below). Some assets will be managed in a document-centric store (MongoDB).
Discovery, access, reuse#
The open-source Girder data management platform is extended to meet the specific needs of the IMQCAM initiative. Girder provides core abstraction capabilities for data organization (files, items, folders, and collections); user management and authentication; access control and authorization; and REST-based APIs. Girder’s plugin architecture simplifies the process of implementing custom user interface components and REST APIs. Custom plugins will be developed for the visualization and analysis of specific data formats (see, for example, the SEM viewer). The Whole Tale platform, described below, is implemented in part as a set of Girder plugins.
Transparent and reproducible analysis#
The Whole Tale platform for transparent and reproducible computational research provides access to customizable and interactive analysis environments. Researchers can easily launch custom containerized environments based on JupyterLab, RStudio, and MATLAB to access and analyze IMQCAM data. These composite research objects–called tales–can be shared with other users or published to external research repositories.
Materials data model#
The IMQCAM data management platform has adopted the GEMD (Graphical Expression of Materials Data) as the primary model for describing and relating materials, the processes that produced them, and the measurements that characterize them. All HTMDEC seedling data will be modeled and stored via GEMD to facilitate querying and analysis. GEMD data is stored in a separate graph database, referencing file assets stored in Girder.
Data management challenges#
The IMQCAM initiative presents distinct challenges for data management. Individual seedlings have well-established and often complex local data management practices that must be adapted and integrated into a centralized model. The success of the initiative requires access to experts within each seedling. Challenges include:
Integration of experimental and computational research data
Enabling both experiment- and materials-centric views of data
Data integration across multiple organizations
Adapting to local data management practices
Tracking provenance of research artifacts including data lineage, provenance, materials history, and experimental context